Interpretable Intelligence: AI you can Understand and Trust
Author:Julius Adebayo, Co-Founder & CEO
Published:March 19, 2026
Originally published December 2nd, 2024. Edited March 19th, 2026.
The march toward superintelligence is afoot, yet AI systems are becoming more capable and opaque in equal measure, precisely because of the way they are built.
The traditional response of reverse engineering already trained models has produced plausible-looking explanations, but failed to deliver
systems we can reliably steer and understand.
At Guide Labs, we are pioneering Interpretable Intelligence, a new paradigm
in which models are engineered, from the ground up, to be auditable, steerable,
and understandable. To demonstrate this, we built Steerling-8B, the first
large-scale inherently interpretable language model, unlocking concept discovery,
inference-time steering, and full training data traceability. This demonstrates that capability and understanding are not at odds.
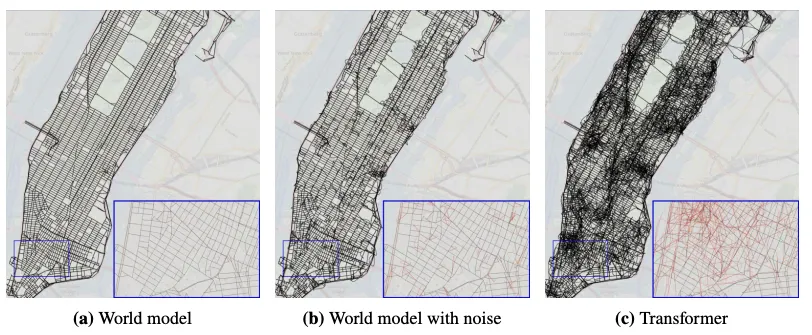
A transformer large language model (LLM) trained on Manhattan taxi rides can give turn-by-turn directions with near-perfect accuracy, yet its internal map of the city is incoherent: streets with impossible orientations, flyovers above other roads, a tangle that bears no resemblance to Manhattan.
The model performs correctly while understanding nothing.
Internal world model of various transformer models trained on turn-by-turn Taxi directions in New York City. Image from Vafa et al. (a) True Manhattan Map. (b) True map with noise perturbations, which still maintains clean spatial representations (c) A transformer trained on turn-by-turn direction produces entangled, chaotic internal states, despite
generating correct predictions. Capability and internal coherence are not the same thing.
Current AI systems achieve feats only a select few humans can match, such as gold medal performances at the International
Mathematical Olympiad, the International Olympiad in Informatics, and the International Collegiate Programming Contest.
These systems are also increasingly used in real world settings where we expect them to meet strict standards for reliability and accountability, such as screening job candidates, assisting clinicians, legal discovery, and helping synthesize potential drug candidates.
Capability does not guarantee reliability. Before AlphaGo’s historic match against Lee Sedol, the Google Deepmind team invited European champion, Fan Hui, to probe the system’s strengths and weaknesses.
He uncovered a critical flaw, stating: “I played with AlphaGo to understand where is the strong points of AlphaGo and where is maybe the weakness… And I find something, I find big weakness about AlphaGo. It’s a big one.”
Project lead, David Silver, explained the underlying difficulty: “There will be these tricky lumps of knowledge it understands very poorly… It can be completely delusional.”
Despite this weakness, AlphaGo produced Move 37: one of the most creative moves in Go’s history.
AlphaGo is capable of both superhuman creativity and deep, invisible flaws, within the span of a single match.
Superhuman insight and invisible failure modes, within the same system.
These failures occur because modern AI systems remain fundamentally opaque and inscrutable.
Today’s models use dense, entangled internal states that neither researchers nor developers can reliably understand.
When a system produces an output, we lack reliable tools to see which mechanism caused it, why it occurred, or how to correct it.
Post hoc interpretability is reading tea leaves
The most popular contemporary paradigm for interpretability is to take an already-trained model and try to reverse engineer what it has learned.
It relies on the belief that, perhaps, the model training process, on the right data, results in models whose internal representations are magically modular and cleanly organized in a way that would make them auditable.
As we will discuss: this desire, while admirable, is false. It is trying to understand an organism that was never designed to be understood; to find structure in a system whose internal organization emerged purely from the pressure to predict the next token.
Feature Attributions
Let’s take a now classic interpretability tool: feature attributions. These are methods that indicate what part of the input a model’s output is most
sensitive to. Used carefully, and with knowledge of how a model was trained,
they can provide genuine insight into model behavior. The problem arises when they are applied to models with no constraints on how
they organize their sensitivity to inputs. Without that, the tool has no way to
distinguish a meaningful explanation from a coincidental one.
Let’s stress test this approach with a simple experiment for an image AI system. We will simply randomize the last layer
of that model, and then compare the output of these feature attribution methods on the partially randomized model to those on a normal model. In the image below, we show an example from a system that is trained to recognize objects.
Fifteen feature attribution methods applied to a model whose last layer is randomly initialized.
These popular methods produce human-plausible outputs even when the model’s weights
are partially destroyed. An explanation that cannot distinguish a trained model from a broken
one is not explaining the model.
Sparse Autoencoders (SAEs)
More recently, Sparse autoencoders (SAEs) have become the dominant technique in mechanistic
interpretability, decomposing activations into human-readable features. They have been shown to surface striking features
inside large models: concepts like the Golden Gate Bridge, emotional states, and
even representations linked to safety-relevant behaviors. But the same problem that haunted feature attributions returns in a new form.
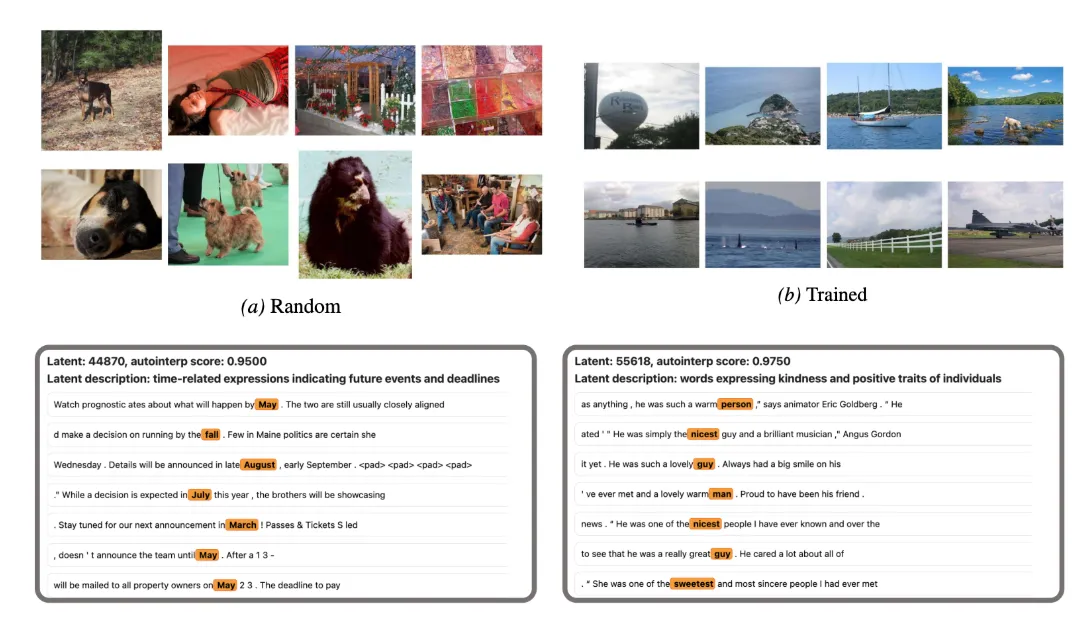
Top (a): Comparison of Random vs. Trained SAE Features on CLIP ViT-B/32 (Layer 3). Bottom: Sample activation contexts for latents from an SAE trained with a Soft-Frozen
Decoder. Image taken from Korznikov and Galichin et. al.
The problem is not that current interpretability tools are poorly designed, or that
reverse engineering an AI system is the wrong target. It is that they are being
applied to an underspecified substrate. Post-hoc interpretability methods work by
making assumptions about how a model organizes its knowledge, but modern models
are trained with no constraints on that organization whatsoever. The model is free
to represent the same concept in several different ways, and the interpretability
tool has no way to know which one is meaningful. For any post-hoc tool to be
reliable, one needs to understand, and ideally intervene on, the model’s training
process. This makes it possible to shape the model to respect the kind of structure
the tool is looking for. Without that, one is not reading the model. One is reading
tea leaves.
At Guide Labs, we are pioneering Interpretable Intelligence, a new paradigm in which models are engineered, from the ground up, to be transparent, controllable, and understandable.
These models have human-interpretable concepts built into their computational structure, and therefore are inherently interpretable.
We do not consider reliability and interpretability as afterthoughts, we design the AI system to inherently satisfy these requirements.
Consequently, we shift the question from “Can we reverse-engineer what this model knows?” to simply: “What did this model learn?”
Until recently, it was widely assumed that building large-scale interpretable models
was impossible without sacrificing performance.
Over the past year, we have shown this assumption to be false.
Unlike post-hoc approaches, Steerling-8B surfaces concepts directly
from its architecture: every output token is attributed at inference time.
We built Steerling-8B: the first large-scale interpretable large language model (LLM) that can trace any token it generates to its input context, concepts a human can understand, and its training data.
Trained on 1.35 trillion tokens, it achieves downstream performance within range of models trained on 1.5–7 times more data, while remaining fully transparent by design. Any token it generates can be traced to its input context, to
human-understandable concepts, and to its training data.
Steerling-8B unlocks several capabilities which include suppressing or amplifying specific concepts at inference time without retraining, training data provenance for any generated chunk, and inference-time alignment via concept control, replacing thousands of safety training examples with explicit concept-level steering.
Building Interpretable Intelligence
Interpretable Intelligence is not a single technique. It is a stack built from
the ground up so that every layer supports the next. We started with data, built
a model whose representations are transparent by design, and then demonstrated
what that transparency makes possible.
Data: Atlas
We built Atlas,
an automated system that annotates trillion-token datasets with human-interpretable
concepts. Using this pipeline, we released FineWeb Atlas, a 10 billion token
concept-annotated pretraining corpus with 16,790 human-understandable concepts
assigned at the sub-document level. FineWeb Atlas makes concept-level data curation
straightforward for the first time.
Model: Steerling-8B
We trained Steerling-8B, the
first 8-billion-parameter inherently interpretable language model, on 1.35 trillion
tokens. Rather than entangling knowledge in inscrutable weight matrices, Steerling
organizes its knowledge into representations that humans can directly read and edit. It enables
decomposing every prediction into per-concept contributions across approximately
33,000 supervised concepts, 100,000 discovered concepts, and a residual component.
The model achieves downstream performance comparable to models trained on 1.5 to 7 times
more data.
Model weights, code, and a PyPI package are all publicly available:
Because Steerling’s representations are organized around human-understandable
concepts by construction, capabilities that are difficult or impossible with
black-box models become straightforward.
Concept Steering. You can inject, suppress, or compose concepts at inference
time to directly control what the model generates. Take a single neutral prompt and steer it toward tenant-landlord law,
coffee, data visualization, or engine mechanics, with no changes to the prompt
itself.
Concept Discovery. Because Steerling’s representations are trained to be disentangled, we can directly read off what the model has learned, including
concepts it was never explicitly trained to acquire. Among the ~100K discovered
concepts: British English spelling as a distinct representation, “you” unified
across six languages with no multilingual training signal, and a dedicated
representation for broken Unicode. In standard models, recovering this kind of
knowledge requires post-hoc methods that face irreducible ambiguity.
Alignment without Finetuning. For any output Steerling-8B generates, we can trace which specific training documents drove it, from forum posts behind harmful content to academic papers behind specialized knowledge.
When behavior is wrong, we can suppress the responsible concepts at inference time rather than retraining from scratch.
This reduces harmful outputs from 80% to 29%, exceeding the effect of finetuning on 10,000 labeled examples and replacing slow, opaque correction loops with explicit, auditable, concept-level controls.
A model that gives perfect directions while holding an incoherent map of the city is not a foundation you can build on.
Steerling is the first large-scale language model that performs and understands, and that changes what AI can be trusted to do.