Scaling Inherently Interpretable Language Models
Abstract
We are releasing a technical report on a different scaling paradigm for language models: capability and interpretability can improve together.
The standard assumption is that interpretability is a tax. You train the strongest opaque model you can, then try to explain it afterward. We test the opposite approach: build interpretability into the training process, then scale it. Across autoregressive and causal-diffusion language models trained over three orders of magnitude of compute, we find that when designed properly, both capability and interpretability improve with scale. The model learns more disentangled representations and becomes easier for humans to understand as it grows. The result is Steerling-8B, a language model that traces any output to the input tokens that mattered, the human-understandable concepts that drove it, and the training data it resembles.
A Recipe for Building Interpretable Models
We present a general recipe for building interpretable language models. The recipe follows the standard pipeline for training language models (data curation, architecture and loss design, optimization, and evaluation) but modifies each stage to introduce human-interpretability constraints.
The recipe for training an interpretable model.
Capability and Interpretability Improve Together
Interpretability improves with scale. Our models route their predictions through concepts: human-understandable topics like gradient descent, state elections, or Mediterranean cuisine. This lets us measure interpretability directly, by asking four questions of the model as it trains:
- Does the model detect the right concepts in a given text?
- Do the concepts stay cleanly separated from each other?
- How much of each prediction flows through concepts, rather than through an uninterpreted residual?
- Do the concepts the model learns actually mean what their labels say?
on both autoregressive and diffusion language models, we tracked all four across three orders of magnitude of compute. Every one improves as models scale.
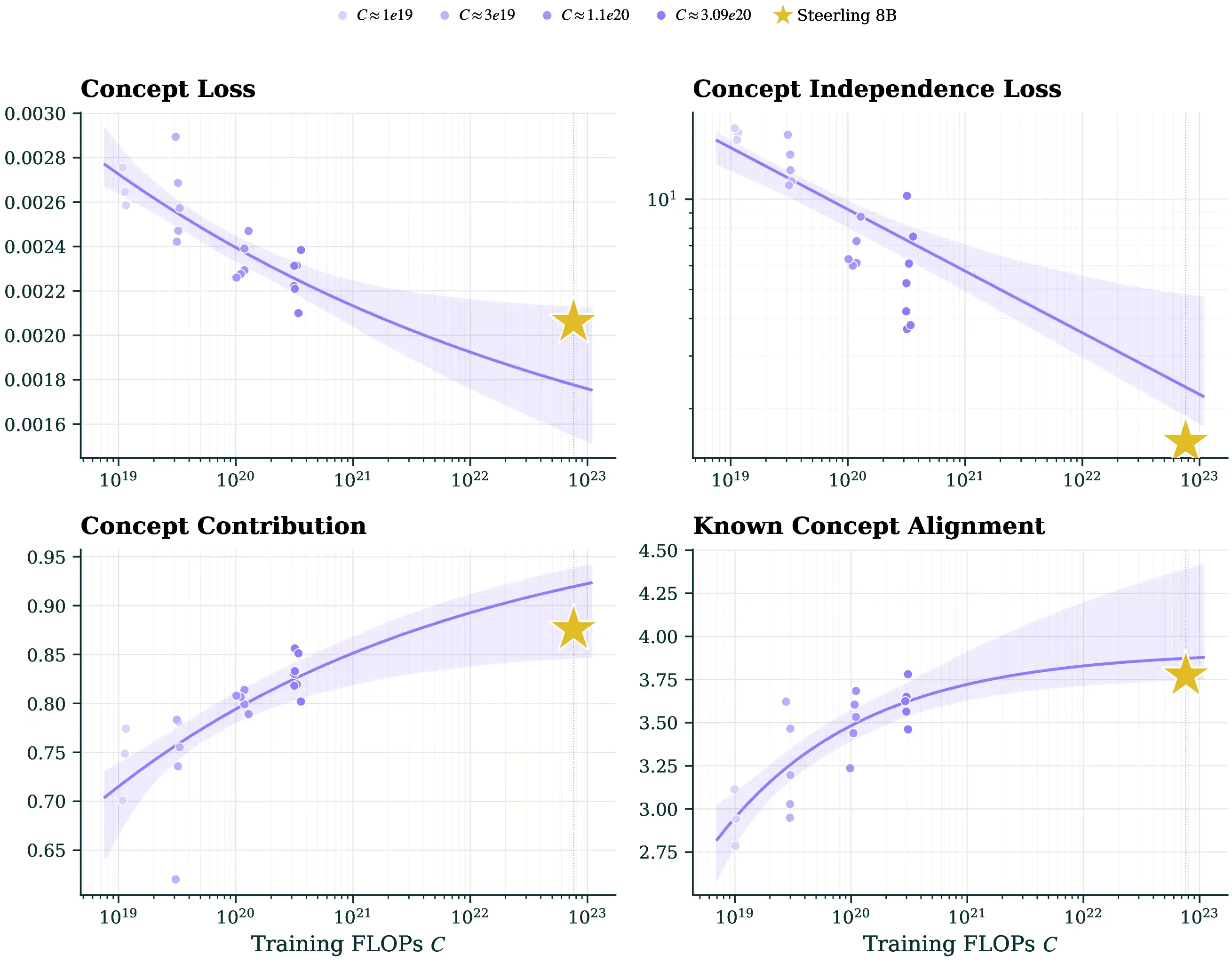
The four interpretability measures against training compute. Top row: concept detection error and concept entanglement (lower is better). Bottom row: the share of each prediction flowing through concepts, and how well concept embeddings match their human labels (higher is better). Stars: Steerling-8B, landing close to predictions made from much smaller models.
Under the metrics we measure, the model does not become harder to understand as it scales. It becomes easier.
And the cost is a fixed offset, not a growing tax. To test whether interpretability hurts capability, we trained four families of models, autoregressive and diffusion, each with and without the concept module, across three orders of magnitude of compute, and compared the best loss each family achieves at every compute budget. The interpretable models track their opaque counterparts with the same slope and a small constant gap. The gap does not grow as models get bigger. The fits are also predictive: Steerling-8B’s final loss was forecast from much smaller models to within nats.
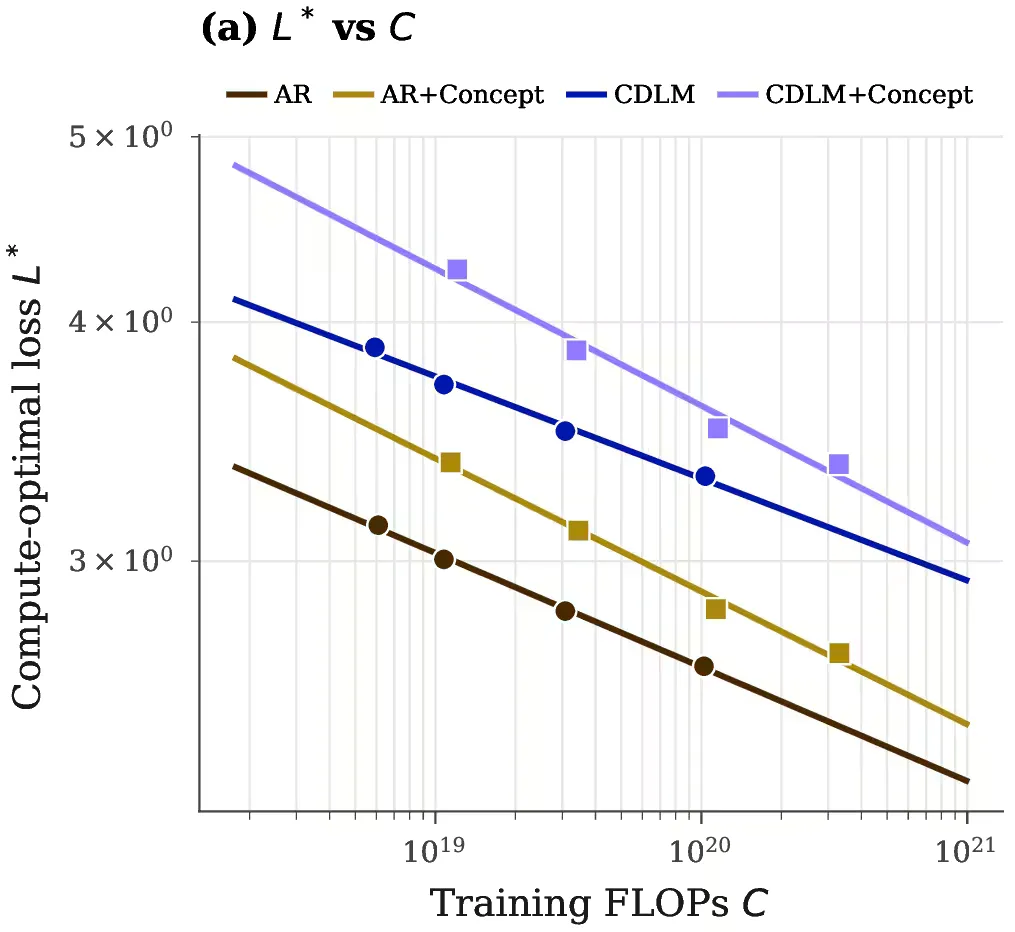
Best achievable loss at each training compute budget (lower is better), for autoregressive (AR) and diffusion (CDLM) models with and without the concept module. The +Concept lines run parallel to their baselines: interpretability costs a small fixed offset, not a penalty that compounds with scale.
A growing penalty would make interpretability impractical exactly where it matters most: at frontier scale. We observe the opposite.
The recipe is also forecastable. We fit scaling laws on much smaller models and extrapolated. The deployed model landed within nats of the prediction. Interpretable models can be planned the same way opaque ones are.
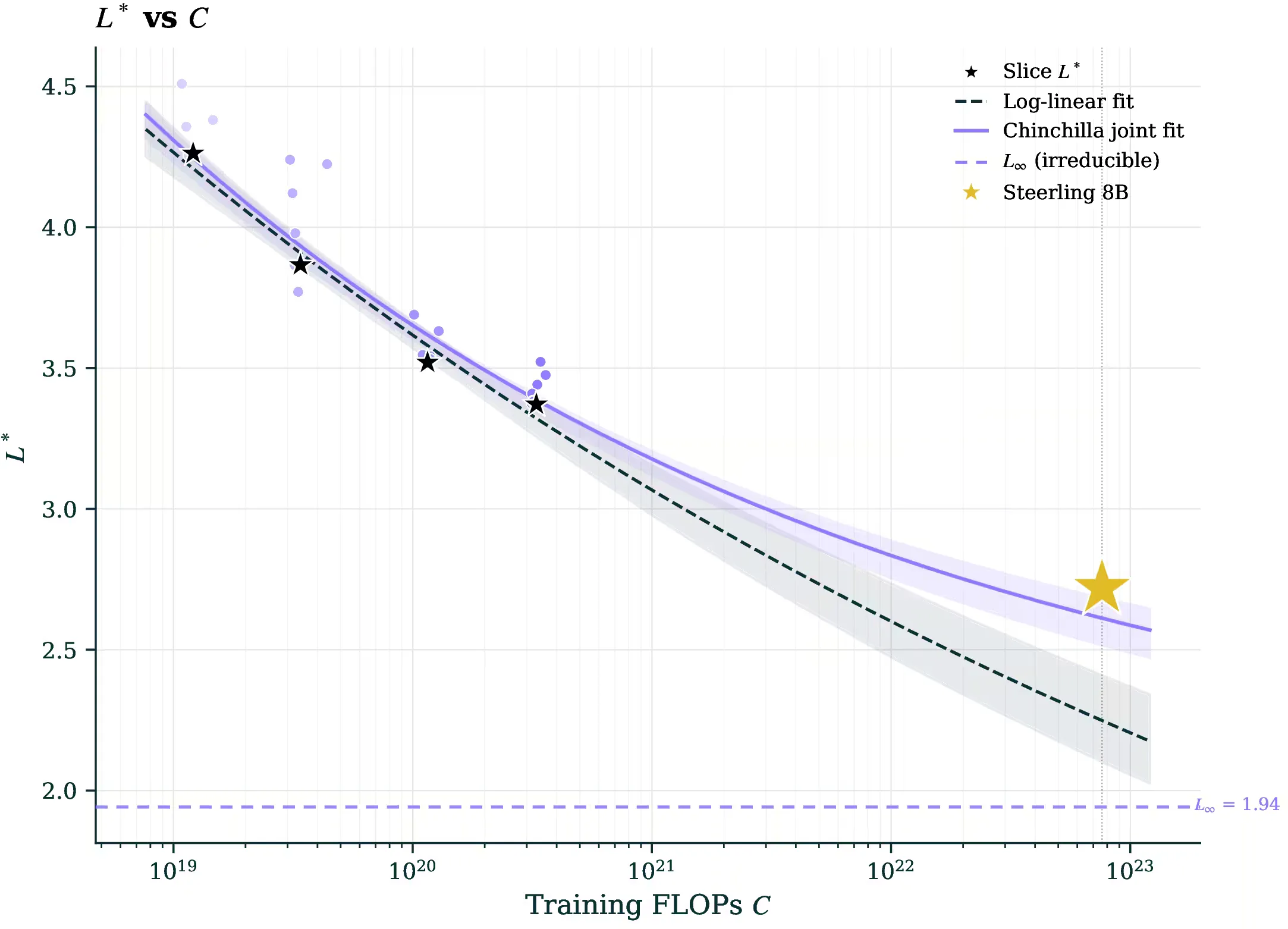
Predicting Steerling-8B from small models. The curve is fit only on small-scale runs (open stars) and extrapolated three orders of magnitude to the right. Steerling-8B (filled star) lands within 0.10 nats of the forecast.
Interpretability Capabilities
For any output, the model traces its prediction along three axes:
- to the input tokens that affected the output, which is measured by replacing each token with a learned “blank” the model was trained to understand;
- to the human-understandable concepts in its internal representations that contributed directly to the output; and
- to the training data the output most resembles.
Every output is attributable: which prompt tokens mattered (input attribution), which concepts the model used (concept attribution), and which training data the output resembles (training-data retrieval).
From explanation to control. The same interfaces support intervention. Each concept is a direction the model itself uses to compute. Amplify or suppress it and behavior changes — no retraining, no new data. Generate, inspect the concepts, retrieve similar training data, steer away from the responsible concept, verify immediately.
Data
We built Atlas, an automated pipeline that annotates language-modeling corpora with human-understandable concepts. Atlas annotated over 1 trillion-token corpus spanning web text, scientific writing, and code with more than 33,000 concepts.
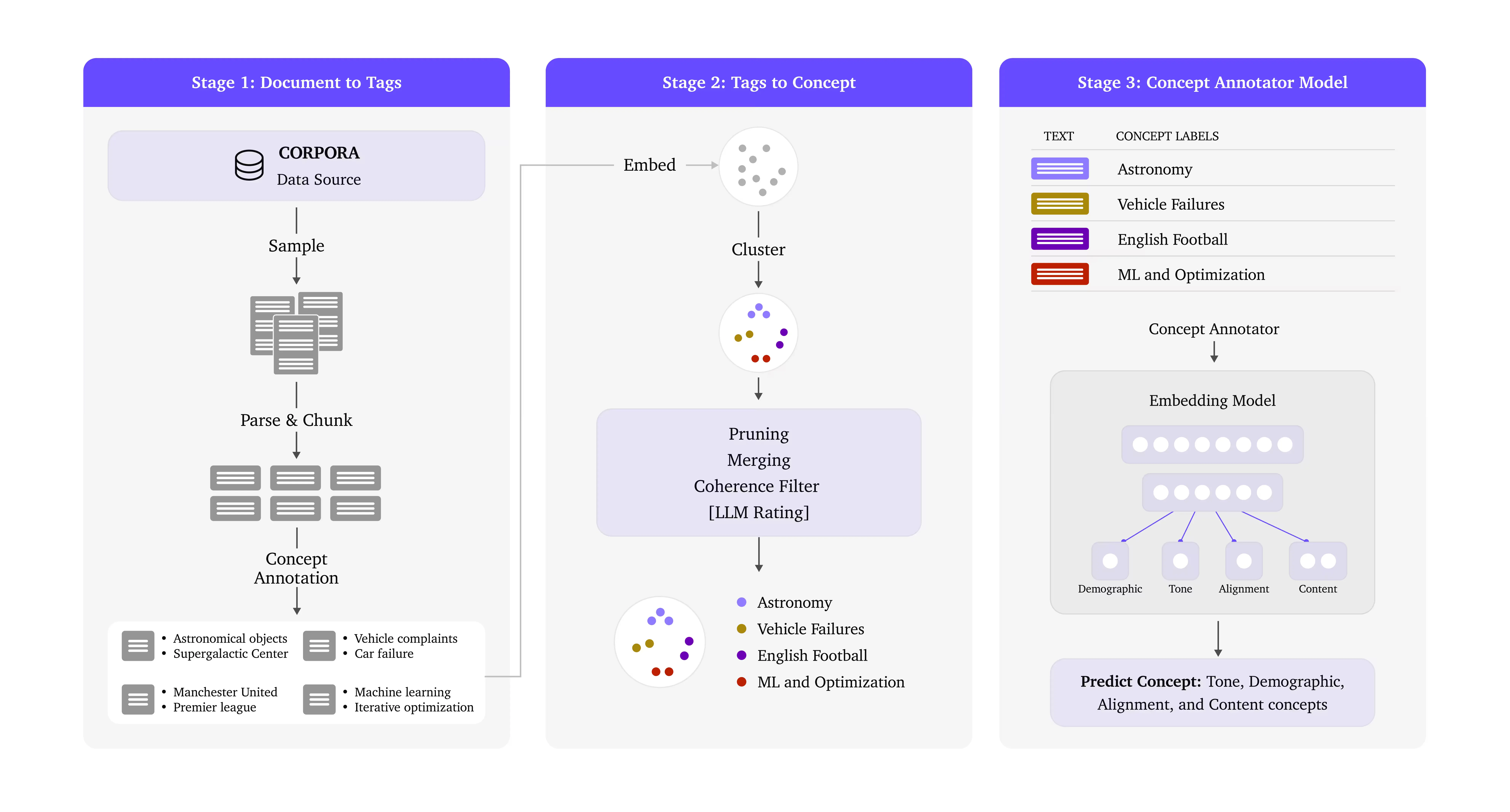
The Atlas three-stage pipeline: documents are chunked and tagged, tags are canonicalized into a concept library, and a concept annotator model is trained for scalable annotation.
Architecture
The model’s internal state is rebuilt as a sum of three parts before making its prediction: concepts we supervised, concepts the model discovered on its own, and a leftover residual. Because the prediction head is linear on top of this sum, each output decomposes into exact per-concept contributions.
The concept module. The transformer hidden state is decomposed into known concept contributions , unknown concept contributions , and a residual .
Evaluation and Results
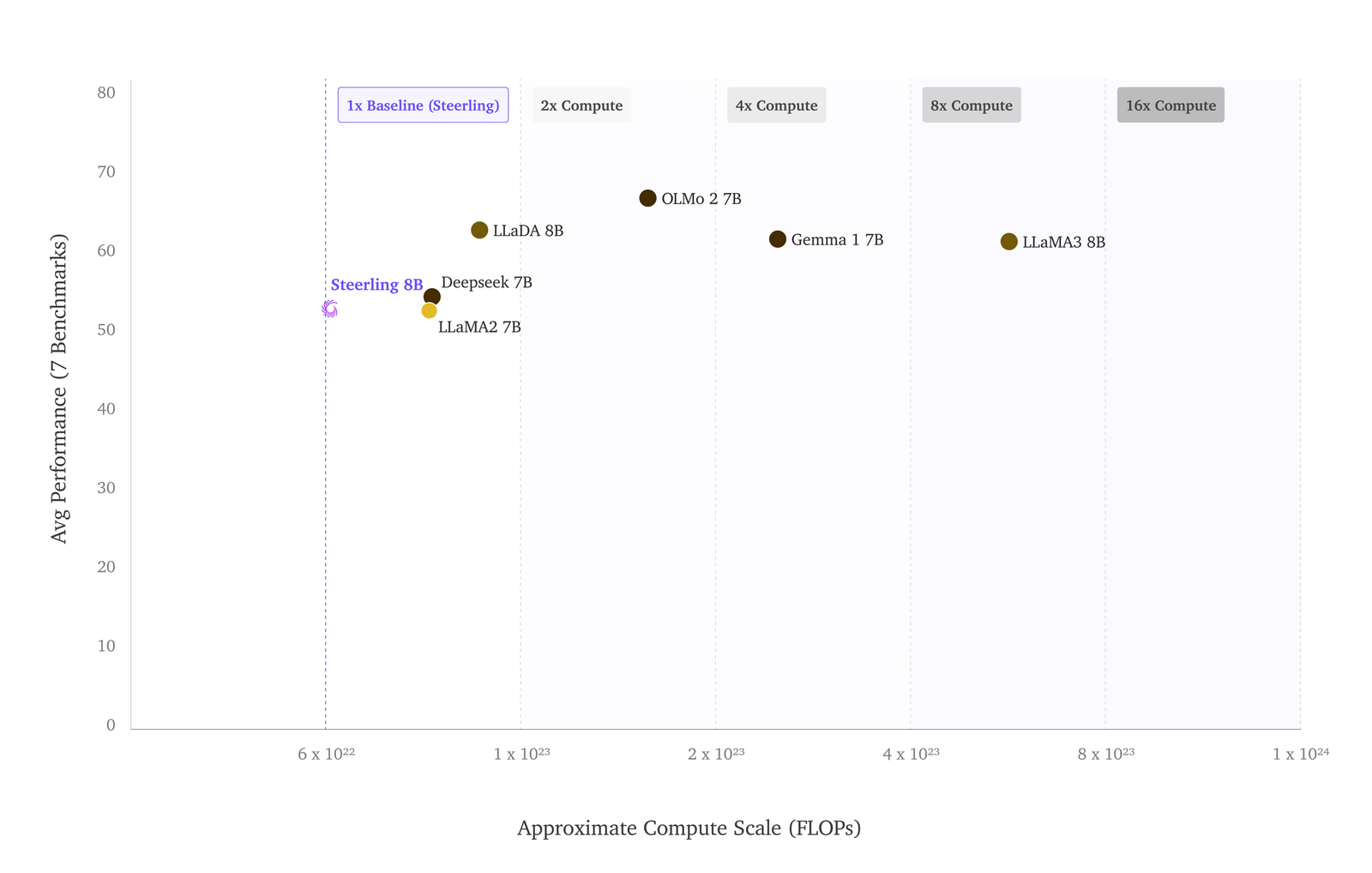
We compare Steerling-8B against open base models of comparable size on seven benchmarks. Every peer was trained on 2 to 16× more compute, yet Steerling-8B lands within ∼10% of them on average and ahead of the models trained at comparable budgets.
| Model | Compute | HSwag | WinoG | PIQA | MMLU | ARC-C | GSM8K | Math | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Steerling-8B | 1× | 70.3 | 64.2 | 75.9 | 46.4 | 52.3 | 44.4 | 8.0 | 51.6 |
| LLaMA2 7B | ~2× | 76.0 | 72.5 | 79.1 | 45.9 | 46.3 | 13.1 | 4.3 | 48.2 |
| DeepSeek 7B | ~2× | 75.4 | 70.5 | 79.2 | 48.2 | 48.1 | 17.4 | 6.0 | 49.3 |
| LLaDA 8B | ~2× | 70.5 | 74.8 | 73.6 | 65.9 | 45.9 | 70.3 | 31.4 | 61.8 |
| OLMo 2 7B | ~4× | 83.8 | 77.2 | 80.1* | 63.7 | 79.8 | 67.5 | 19.1* | 67.3 |
| Gemma 1 7B | ~5× | 81.2 | 72.3 | 81.2 | 64.3 | 53.2 | 46.4 | 24.3 | 60.4 |
| LLaMA3 8B | ~16× | 79.1 | 77.3 | 80.6 | 65.4 | 53.1 | 48.7 | 16.0 | 60.0 |
Compute is approximate training FLOPs relative to Steerling-8B. * Scores reported from external evaluations.
Why This Matters
Post-hoc explanations have no guarantee of being faithful, because the model was never trained to make them valid. The alternative is to make interpretability part of the training contract.
Steerling-8B is a first step: not a fully transparent model, but a large language model with an inspectable interface built into the forward pass. One that improves rather than degrades with scale.
If interpretability can be specified, trained, and scaled like other capabilities, then opacity is not an unavoidable property of powerful AI systems.
Read the technical report here