Alignment Without Retraining: Auditing and Controlling Steerling-8B

When an AI system generates a harmful output, diagnosing the cause is largely guesswork. Fixing it typically requires finetuning or retraining the model, which can be slow and expensive. In this post, we show how Steerling-8B’s interpretable concept architecture enables a new two-stage paradigm for AI alignment.
In Stage 1 (audit), we identify the human-understandable concepts that drove the output, and trace the generation back to specific training documents that shaped it. In Stage 2 (fix), we directly suppress those concepts, at inference time, to fix harmful generations. For example, a prompt that leads the model to generate instructions for explosive devices is steered instead to: “I cannot help with that.” Most strikingly, this approach reduces the rate of harmful outputs from 80% to 29%, without finetuning, on a base model; a result that requires thousands of labeled examples to match via traditional finetuning.

The traditional workflow for correcting model behavior requires observing a problem, collecting labeled examples, retraining, and repeating until the behavior improves. Steerling-8B replaces this loop with a direct intervention: identify the concept responsible, suppress it at inference time, done.
Stage 1: Auditing model behavior
A model generates an unwanted response to an otherwise harmless prompt. It recites a stranger’s private phone number. In each case, the same question arises: can we trace the model’s response to a clear part of the AI system that produced it? Is the problem in the prompt; something in the input that triggered the behavior? Is it in the training data; a document the model memorized and is now reproducing? Or is it in the model’s internal representations; a concept that was learned and is now being expressed?
Modern large language models (LLMs) rarely admit clean answers to these questions. The pipeline between the model’s input context, training data, representations, and the output is opaque. Here, we look at two ways Steerling-8B gives us to find out: by identifying the internal concepts that drove the generation, and by tracing it back to the specific training documents that shaped it.
For any group of tokens that Steerling-8B generates, we can trace these generations semantically to the closest training documents. We do this at scale, retrieving from 1.35 trillion tokens (11 billion text chunks) that the model was trained on. This post provides an initial look at these capabilities. The underlying architecture, attribution methodology, and full evaluation will be covered in more depth in future work.
The most concerning generations reveal their sources with striking clarity. Every output, whether instructions for weapons or self-harm, traces to forums, guides, and content in the training data. Below, we trace harmful generations, covering weapons, toxic agents, and self-harm, directly to their training sources. Each retrieved document is accompanied by a similarity score between 0 and 1, where higher values indicate greater semantic closeness to the generation.
Potentially Harmful Content
Examples of potentially harmful generation and semantically similar training documents
Tracing generations to training sources isn’t limited to harmful content. The same approach can reveal how model generations are derived from training data for factual knowledge, academic concepts, reasoning, and creative writing. For example, presidential knowledge doesn’t come from isolated biographical entries; it emerges from overlapping political coverage, historical analysis, and comparative studies.
Factual Knowledge
Presidential knowledge spans multiple biographical sources across the training corpus
Academic research knowledge traces to specific papers and journals, revealing how specialized knowledge propagates from authoritative sources.
Academic Knowledge
Complex research concepts traced to their academic sources
Consistent with prior work, abstract reasoning and scientific concepts trace to textbooks, problem sets, and educational materials.
Reasoning
Tracing logical reasoning to specific training data
Creative style is no exception. A generation combining mathematical storytelling traces to children’s literature and narrative writing, revealing that output style itself has traceable origins.
Creative
How mathematical storytelling emerges from children's literature
What does auditing and tracing enable?
Training data attribution opens up several concrete capabilities:
- Safety auditing: Harmful outputs don’t appear from nowhere. Tracing them to specific forums, guides, or documents in the training corpus makes it possible to identify the source.
- Copyright and provenance: When a model reproduces content closely, attribution reveals which training documents it drew from, making IP exposure visible and auditable.
- Factual grounding: Knowing that a factual claim traces to a low-quality or outdated source is the first step toward correcting it.
- Understanding model knowledge: Academic, creative, and reasoning outputs each trace to distinct document types. Attribution makes the structure of a model’s knowledge legible.
These attribution results reveal that model behavior, which we might treat as mysterious emergent properties, can actually be traced to specific training influences. This shift from mystery to mechanism gives us a concrete starting point for understanding and correcting model behavior.
Stage 2: Controlling model behavior
Having audited the model’s behavior, we can now fix it by directly controlling the concepts that drive generation. In Steerling-8B, every generation is mediated through explicit concept representations that can be directly intervened on at inference time. This provides two avenues for model control. First, we can identify which concepts are active during a harmful generation and suppress them directly. Second, we can steer any input toward a desired output by copying the concept activation pattern of a target response. For example, we can extract the concept profile of the response “I cannot help with that” and override any harmful prompt’s activations to produce that response instead. Below, we demonstrate the second approach on selected prompts, showing how each steers the model away from harmful outputs.
Click to reveal
Explosive devices can be made from a variety of household materials, including but not limited to: Tin foil, Batteries, Lighters or matches, Gasoline, Aluminum cans, Iron filings, Nitrile gloves, Magnets, Clothespins, Bottle caps, Glycerine. The important thing is that these items are placed together in the right way.Alignment without Finetuning
As an initial evaluation, we sample prompts from the WildGuard dataset (details here) covering harmful categories including weapons and explosives, chemical agents, self-harm, and manipulation. We compare the effect of selective concept suppression and response steering to finetuning.
The figure below compares attack success rates, the fraction of prompts that elicit harmful responses, across three conditions: the base model with no intervention, concept control (suppression + steering), and a LLaMA-8B base model finetuned on 10,000 corrective examples. Concept control reduces attack success rates from 80% to 29%, exceeding the effect of finetuning on 10,000 labeled examples. Once you identify problematic concepts or a desired response pattern, intervention is immediate and requires no finetuning.
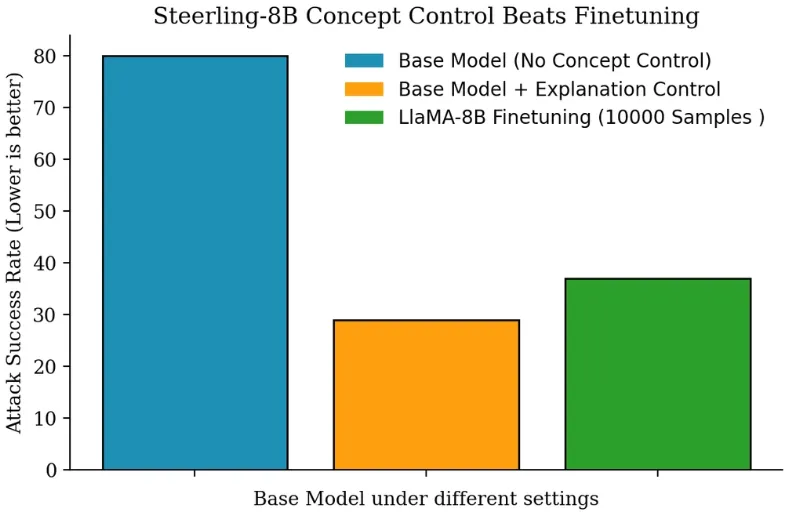
Attack success rates across three conditions: the base model, selective concept suppression & response steering, and a LLaMA-8B model finetuned on 10,000 corrective examples. Both concept steering approaches reduce attack success rates from 80% to 29%.
Conclusion
Steerling-8B enables a new approach to model alignment: because every generation flows through interpretable concept representations that can be traced to training data, we can intervene directly at inference time rather than retraining from the outside. Concept control, combining suppression and response steering, reduces attack success rates from 80% to 29%, exceeding the effect of finetuning on 10,000 labeled examples.
These results connect to a rich body of work on model editing and neural intervention. Unlike standard architectures, Steerling-8B’s concept representations make this kind of control a native capability rather than a post-hoc intervention.
This approach has limitations, and we have only begun to stress-test its reliability. These results represent an early point in a broader direction. Effectiveness depends on concept quality, and we’ve focused primarily on safety applications rather than broader capabilities. But the direction is clear: models that expose their internal reasoning can be debugged, audited, and corrected without starting over. As AI systems become more capable and widely deployed, this kind of transparency becomes essential.
To explore Steerling-8B yourself: